Interpretation of GSFA Results on CD8+ T Cell CROP-seq Data
– for manuscript
Yifan Zhou (zhouyf@uchicago.edu)
1 Introduction
This page demonstrates how to visualize and interpret the results from a GSFA run.
We have described in this page how to run GSFA on CD8+ T cell CROP-seq data from Shifrut et al.
To recapitulate, the processed dataset consists of 10677 unstimulated
T cells and 14278 stimulated T cells.
They belong to one of the 21 perturbation conditions (CRISPR knock-out
of 20 regulators of T cell proliferation or immune checkpoint genes, and
negative control).
Top 6000 genes ranked by deviance statistics were kept. A modified
two-group GSFA was performed on the data with 20 factors specified, and
perturbation effects estimated separately for cells with/without TCR
stimulation.
1.1 Load necessary packages and data
library(data.table)
library(Matrix)
library(tidyverse)
library(ggplot2)
theme_set(theme_bw() + theme(plot.title = element_text(size = 14, hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
panel.grid.minor = element_blank())
)
library(gridExtra)
library(ComplexHeatmap)
library(kableExtra)
library(WebGestaltR)
source("../R/plotting_functions.R")
data_folder <- "../data/TCells/"The first thing we need is the output of GSFA
fit_gsfa_multivar_2groups() run. The lighter version
containing just the posterior mean estimates and LFSR of
perturbation-gene effects is enough. (See
R/run_gsfa_TCells_2groups.R for more GSFA run details.)
The association of \(Z\) with \(G\) were estimated separately for stimulated and unstimulated cells, generating two effect size matrices, \(\beta_1\) and \(\beta_0\), and two \(LFSR\) matrices that summarized the effects of perturbations on genes for stimulated and unstimulated cells, respectively.
fit <- readRDS(paste0(data_folder, "gsfa_fit.light.rds"))
gibbs_PM <- fit$posterior_means
lfsr_mat1 <- fit$lfsr1[, -ncol(fit$lfsr1)]
lfsr_mat0 <- fit$lfsr0[, -ncol(fit$lfsr0)]We also need the cell by perturbation matrix which was used as input
\(G\) for GSFA.
(The row names of which can also inform us which group each cell belongs
to.)
G_mat <- readRDS(paste0(data_folder, "perturbation_matrix.rds"))Finally, we load the mapping from gene name to ENSEMBL ID for all 6k genes used in GSFA, as well as selected neuronal marker genes. This is specific to this study and analysis.
genes_df <- readRDS(paste0(data_folder, "top6k_genes.rds"))
interest_df <- readRDS(paste0(data_folder, "selected_tcell_markers.rds"))
KO_names <- colnames(lfsr_mat1)2 Factor ~ Perturbation Associations
2.1 Perturbation effects on factors (stimulated cells)
Fisrt of all, we look at the estimated effects of gene perturbations on factors inferred by GSFA.
We found that targeting of 9 genes, ARID1A, CBLB, CD5, CDKN1B, DGKA, LCP2, RASA2, SOCS1, and TCEB2, has significant effects (PIP > 0.95) on at least 1 of the 20 inferred factors.
Estimated effects of perturbations on factors:
dotplot_beta_PIP(t(gibbs_PM$Gamma1_pm), t(gibbs_PM$beta1_pm),
marker_names = KO_names,
reorder_markers = c(KO_names[KO_names!="NonTarget"], "NonTarget"),
inverse_factors = F) +
coord_flip()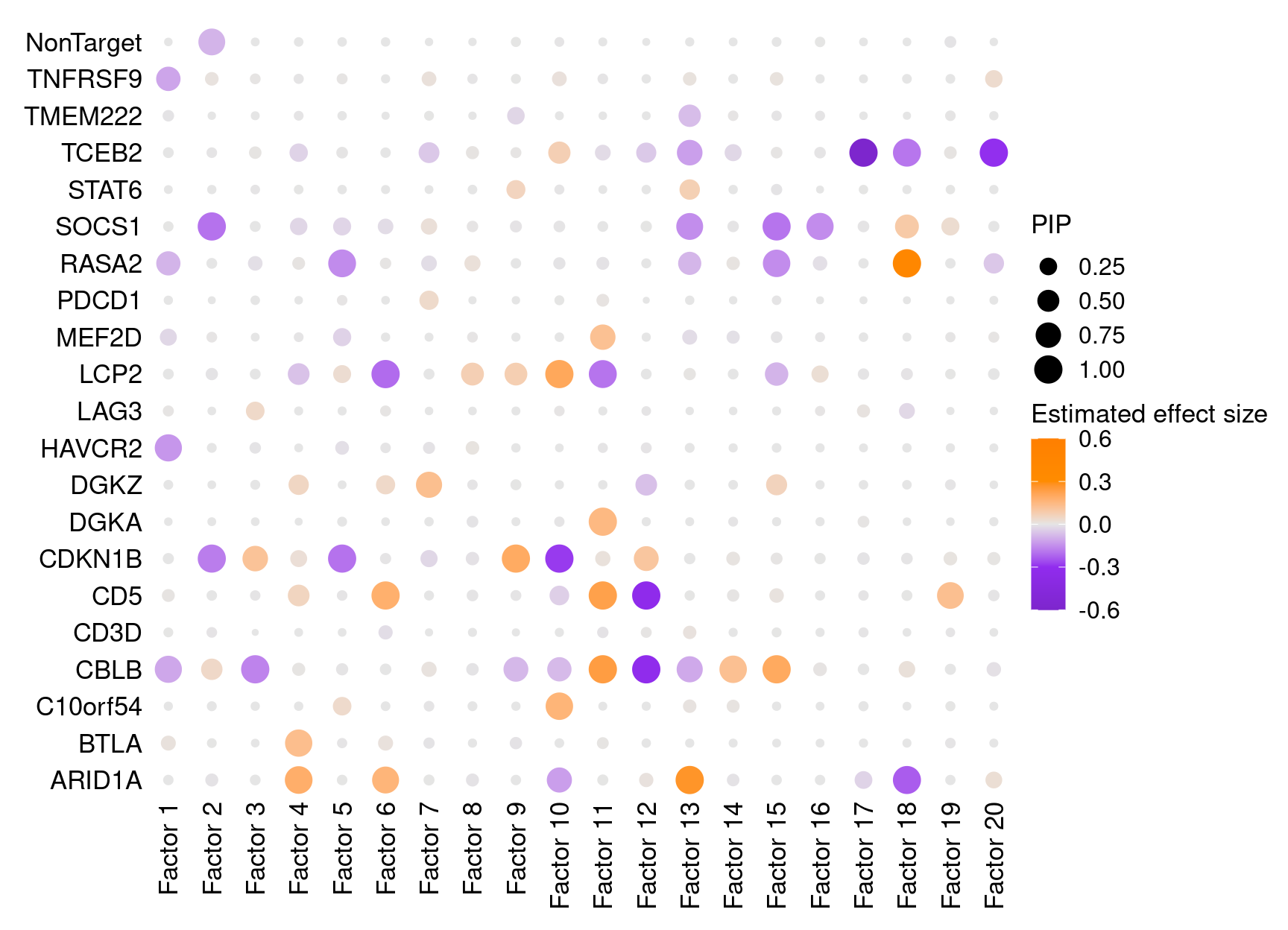
Here is a closer look at the estimated effects of selected perturbations on selected factors:
targets <- c("ARID1A", "LCP2", "CD5", "CBLB", "RASA2",
"DGKA", "TCEB2", "SOCS1", "CDKN1B")
complexplot_perturbation_factor(gibbs_PM$Gamma1_pm[-nrow(gibbs_PM$Gamma1_pm), ],
gibbs_PM$beta1_pm[-nrow(gibbs_PM$beta1_pm), ],
marker_names = KO_names, reorder_markers = targets,
reorder_factors = c(2, 4, 9, 12))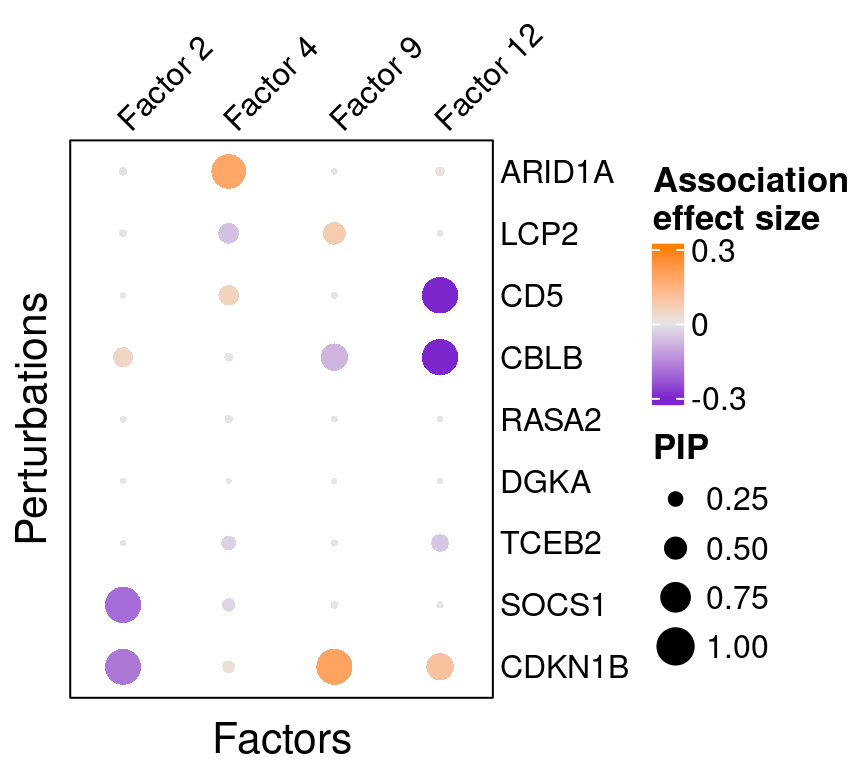
We can also assess the correlations between each pair of perturbation
and inferred factor.
The distribution of correlation p values show significant signals in
stimulated cells.
## Indices of stimulated cells:
stim_cells <-
(1:nrow(G_mat))[startsWith(rownames(G_mat), "D1S") |
startsWith(rownames(G_mat), "D2S")]
gibbs_res_tb <- make_gibbs_res_tb(gibbs_PM, G_mat, compute_pve = F,
cell_indx = stim_cells)
heatmap_matrix <- gibbs_res_tb %>% select(starts_with("pval"))
rownames(heatmap_matrix) <- 1:nrow(heatmap_matrix)
colnames(heatmap_matrix) <- colnames(G_mat)
summ_pvalues(unlist(heatmap_matrix),
title_text = "GSFA Stimulated\n(21 Targets x 20 Factors)")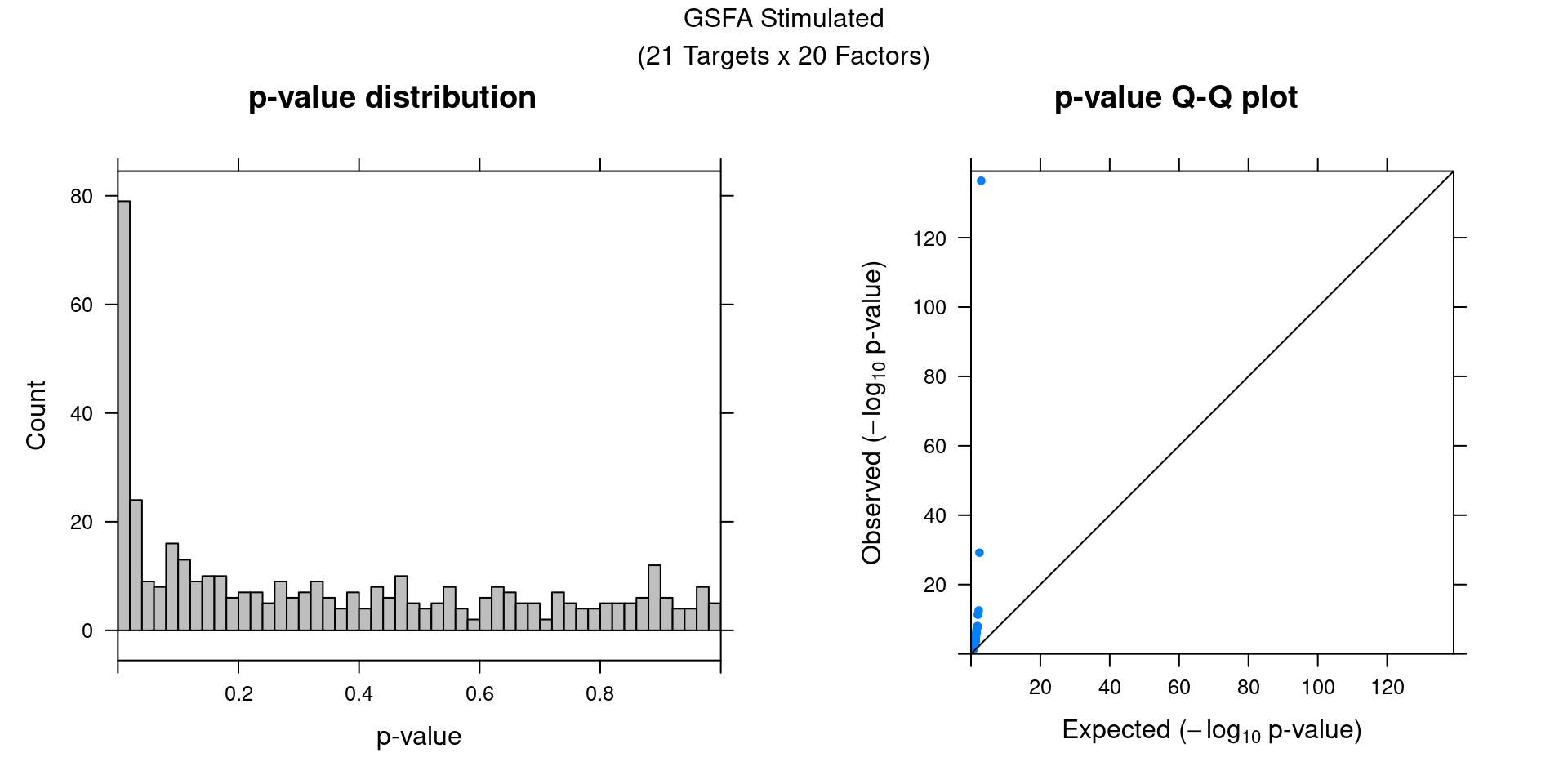
2.2 Perturbation effects on factors (unstimulated cells)
In unstimulated cells, only three pairs of associations were detected at PIP > 0.95, which is unsurprising given the role of these targeted genes in regulating T cell responses:
dotplot_beta_PIP(t(gibbs_PM$Gamma0_pm), t(gibbs_PM$beta0_pm),
marker_names = KO_names,
reorder_markers = c(KO_names[KO_names!="NonTarget"], "NonTarget"),
inverse_factors = F) +
coord_flip()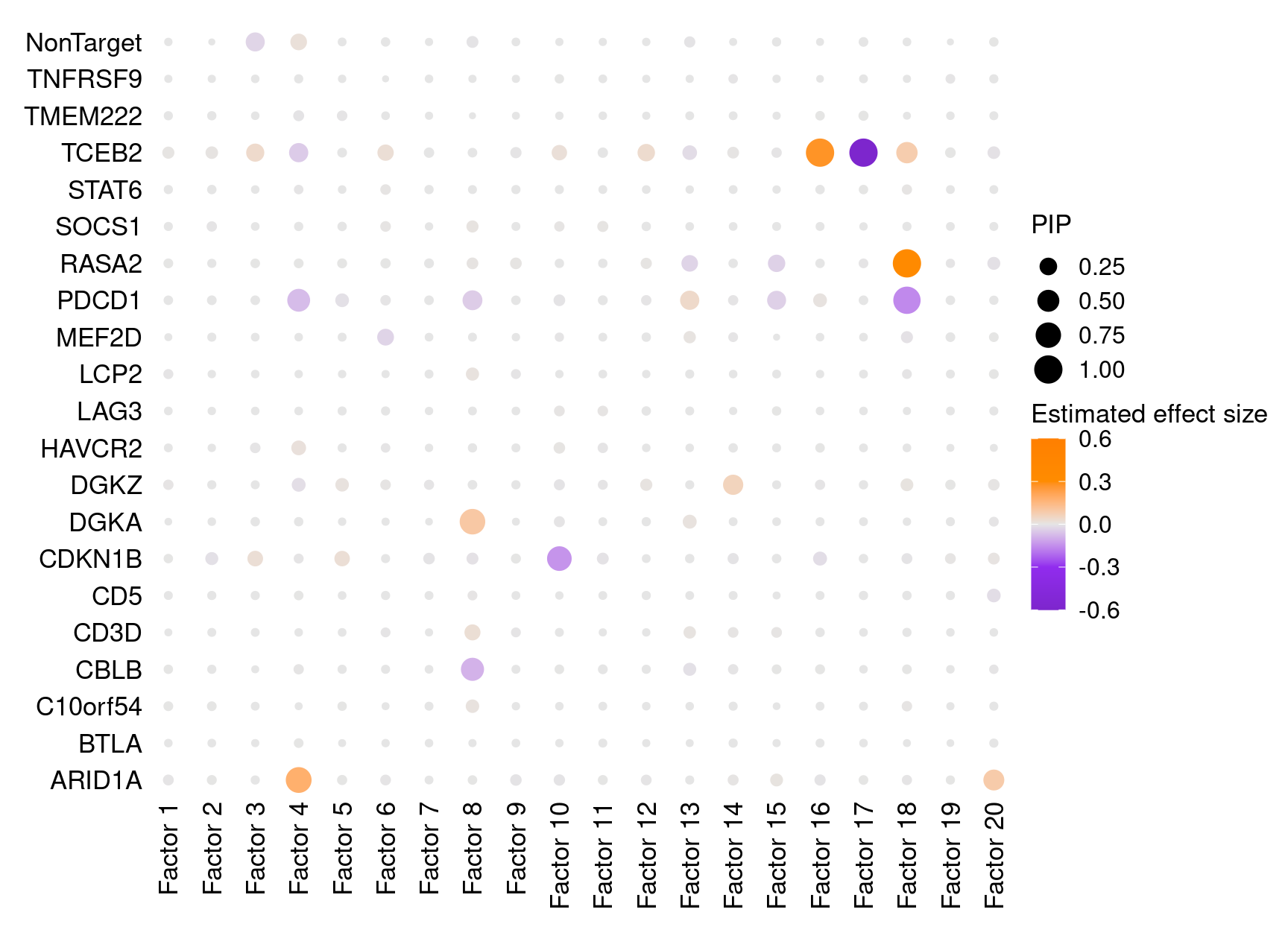
3 Factor Interpretation
3.1 Correlation within factors
Since the GSFA model does not enforce orthogonality among factors, we first inspect the pairwise correlation within them to see if there is any redundancy. As we can see below, the inferred factors are mostly independent of each other.
plot_pairwise.corr_heatmap(input_mat_1 = gibbs_PM$Z_pm,
corr_type = "pearson",
name_1 = "Pairwise correlation within factors (Z)",
label_size = 10)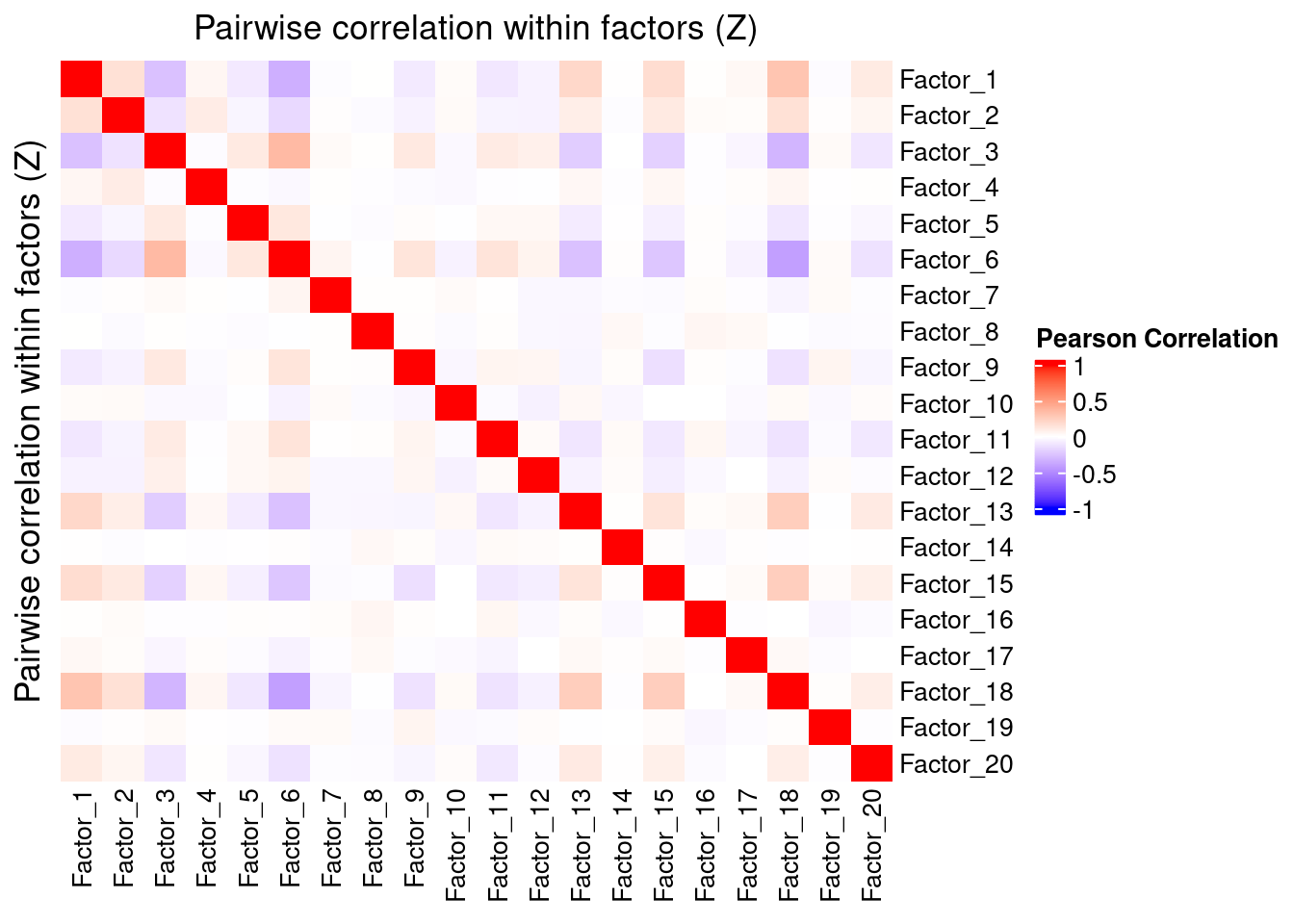
plot_pairwise.corr_heatmap(input_mat_1 = (gibbs_PM$F_pm > 0.95) * 1,
corr_type = "jaccard",
name_1 = "Pairwise correlation within \nbinarized gene loadings (F_pm > 0.95)",
label_size = 10)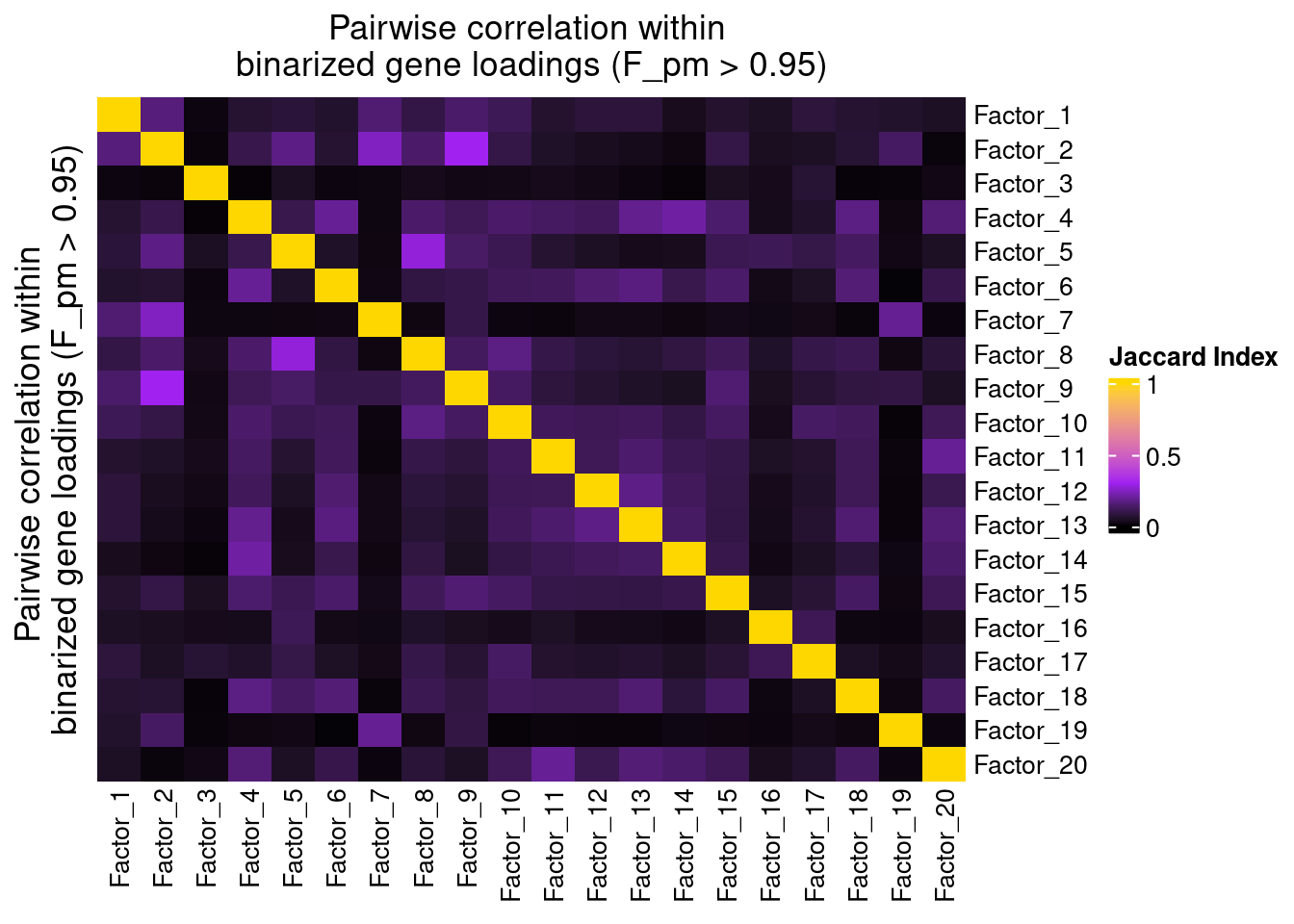
3.2 Gene loading in factors
To understand these latent factors, we inspect the loadings (weights) of several marker genes for T cell activation or proliferation states in them.
| gene_name | type | protein_name | gene_ID |
|---|---|---|---|
| IL7R | T cell resting state | IL-7 receptor | ENSG00000168685 |
| CCR7 | T cell resting state | C-C motif chemokine receptor 7 | ENSG00000126353 |
| GZMB | T cell activation | Granzyme B | ENSG00000100453 |
| IFNG | T cell activation | Interferon gamma | ENSG00000111537 |
| CD44 | T cell activation | CD44 | ENSG00000026508 |
| IL2RA | T cell activation | IL-2 receptor | ENSG00000134460 |
| XCL1 | T cell activation | X-C motif chemokine ligand 1 | ENSG00000143184 |
| TNFRSF18 | T cell activation | GITR | ENSG00000186891 |
| ITGAL | T cell activation | LFA-1 | ENSG00000005844 |
| MKI67 | Cell proliferation | Marker of proliferation Ki-67 | ENSG00000148773 |
| TOP2A | Cell proliferation | DNA topoisomerase II alpha | ENSG00000131747 |
| CENPF | Cell proliferation | Centromere protein F | ENSG00000117724 |
We visualize both the gene PIPs (dot size) and gene weights (dot color) in all factors:
complexplot_gene_factor(genes_df, interest_df, gibbs_PM$F_pm, gibbs_PM$W_pm)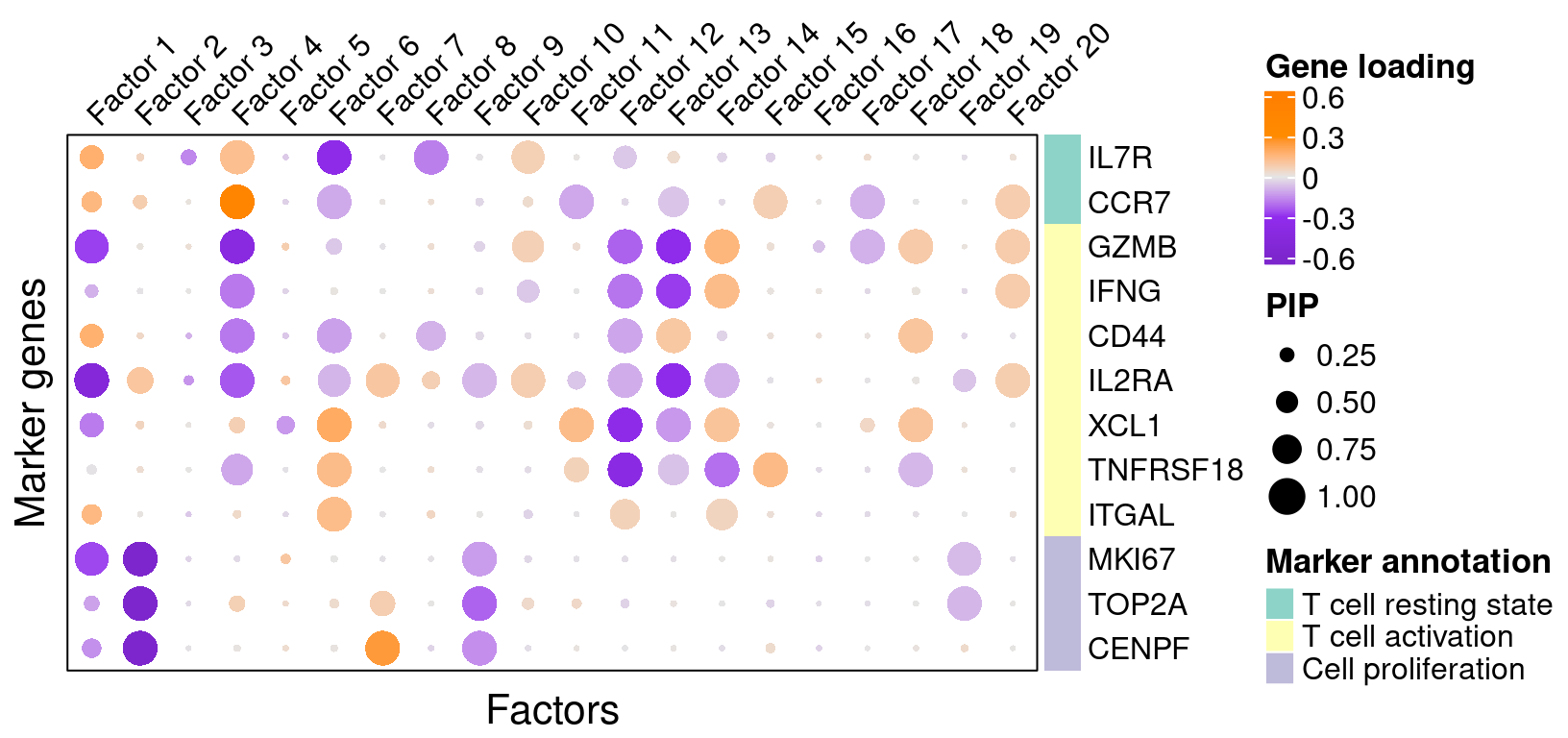
A closer look at some factors that are associated with perturbations:
complexplot_gene_factor(genes_df, interest_df, gibbs_PM$F_pm, gibbs_PM$W_pm,
reorder_factors = c(2, 4, 9, 12))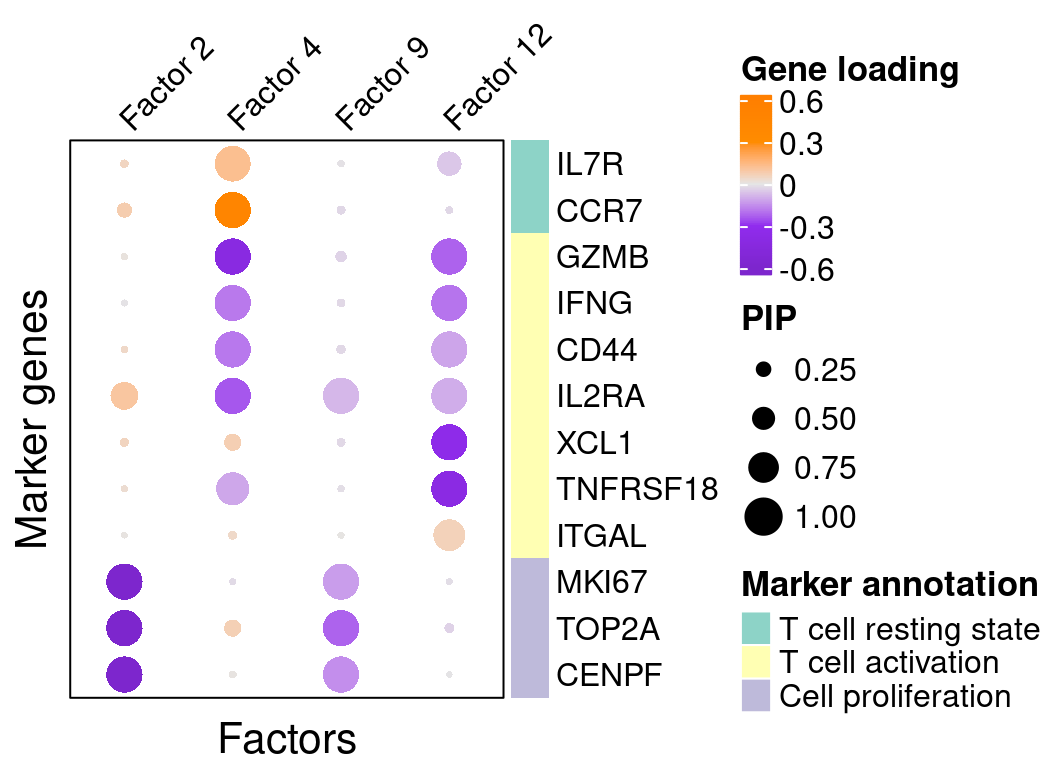
3.3 GO enrichment analysis in factors
To further characterize these latent factors, we perform GO (gene
ontology) enrichment analysis of genes loaded on the factors using
WebGestalt.
Foreground genes: Genes w/ non-zero loadings in each factor (gene PIP
> 0.95);
Background genes: all 6000 genes used in GSFA;
Statistical test: hypergeometric test (over-representation test);
Gene sets: GO Slim “Biological Process” (non-redundant).
## The "WebGestaltR" tool needs Internet connection.
enrich_db <- "geneontology_Biological_Process_noRedundant"
PIP_mat <- gibbs_PM$F_pm
enrich_res <- list()
for (i in 1:ncol(PIP_mat)){
enrich_res[[i]] <-
WebGestaltR::WebGestaltR(enrichMethod = "ORA",
organism = "hsapiens",
enrichDatabase = enrich_db,
interestGene = genes_df[PIP_mat[, i] > 0.05, ]$ID,
interestGeneType = "ensembl_gene_id",
referenceGene = genes_df$ID,
referenceGeneType = "ensembl_gene_id",
isOutput = F)
}Several GO “biological process” terms related to immune responses or cell cycle are enriched in factors 2, 4, 9, and 12:
factor_indx <- 2
terms_of_interest <- c("kinetochore organization", "chromosome segregation",
"cell cycle G2/M phase transition", "cytokinesis")
barplot_top_enrich_terms(enrich_res_by_factor[[factor_indx]],
terms_of_interest = terms_of_interest,
str_wrap_length = 50) +
labs(title = paste0("Factor ", factor_indx))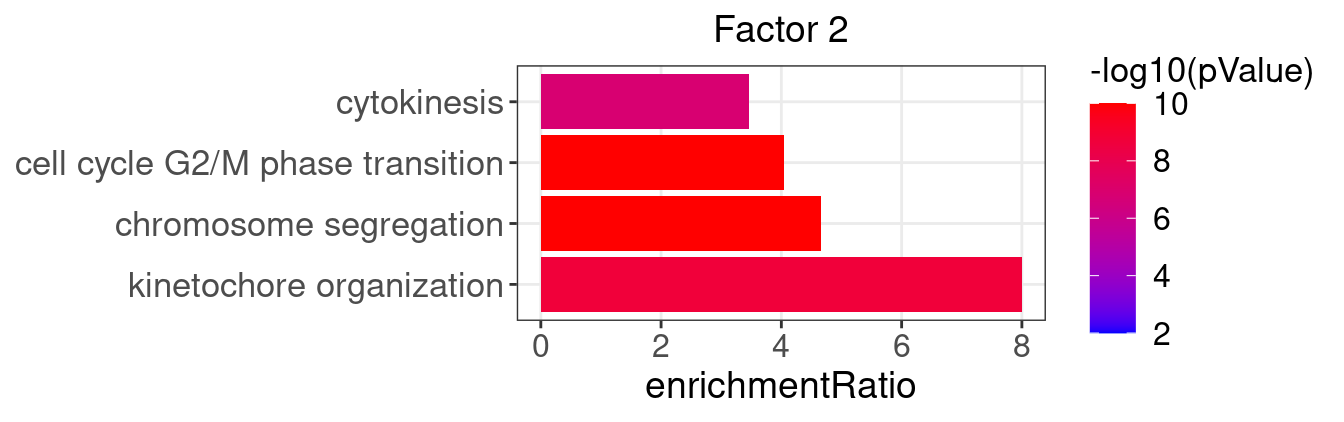
factor_indx <- 9
terms_of_interest <- c("microtubule cytoskeleton organization involved in mitosis",
"chromosome segregation", "cytokinesis", "cell cycle checkpoint")
barplot_top_enrich_terms(enrich_res_by_factor[[factor_indx]],
terms_of_interest = terms_of_interest,
str_wrap_length = 35) +
labs(title = paste0("Factor ", factor_indx))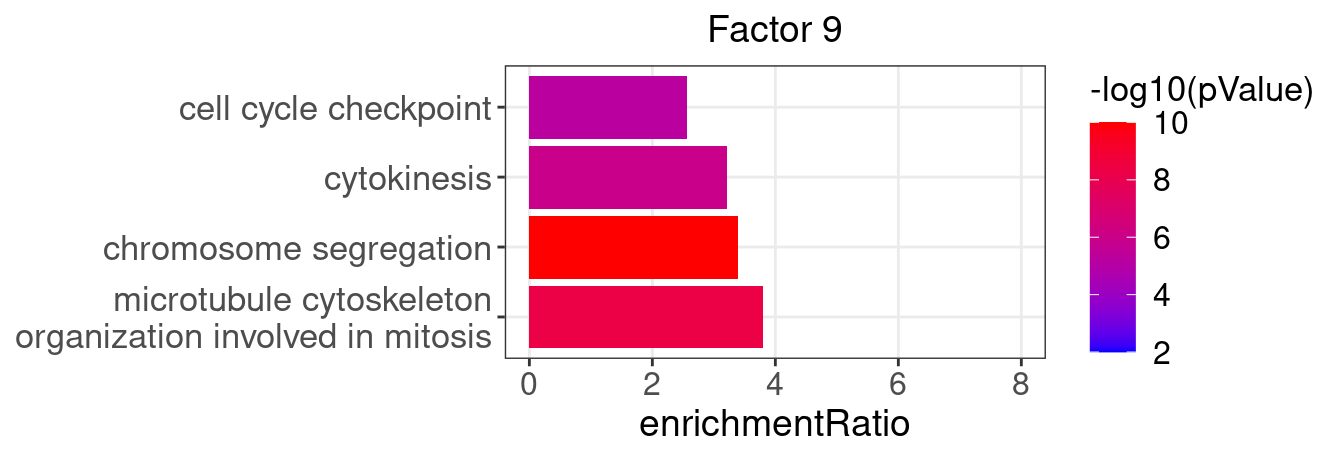
factor_indx <- 4
terms_of_interest <- c("response to chemokine", "cell killing", "leukocyte migration",
"response to interferon-gamma", "cytokine secretion")
barplot_top_enrich_terms(enrich_res_by_factor[[factor_indx]],
terms_of_interest = terms_of_interest,
str_wrap_length = 35) +
labs(title = paste0("Factor ", factor_indx))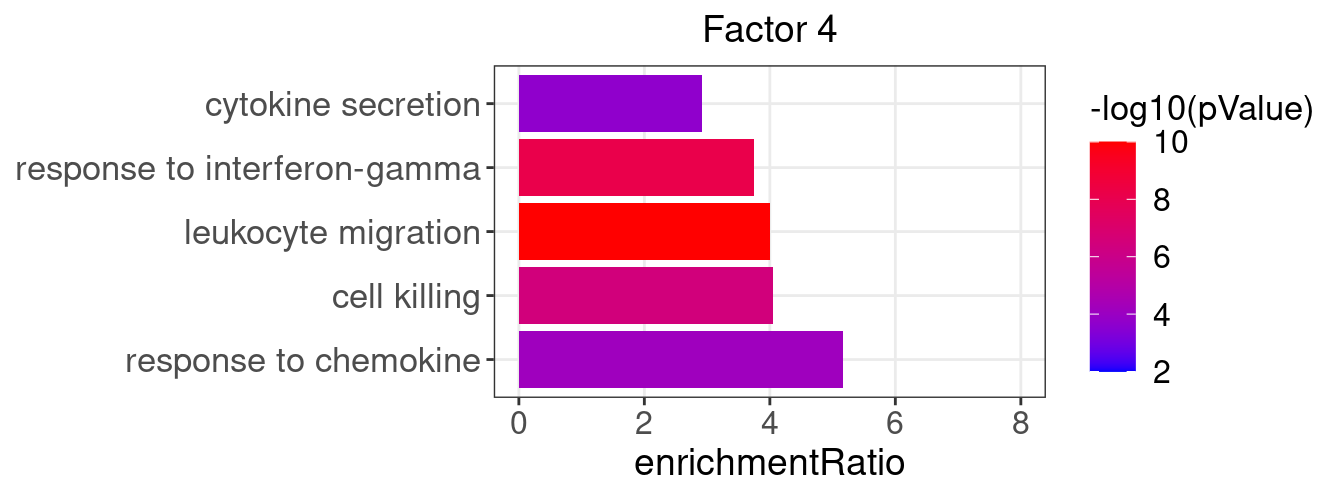
factor_indx <- 12
terms_of_interest <- c("leukocyte cell-cell adhesion", "extrinsic apoptotic signaling pathway",
"cell killing", "T cell activation", "NIK/NF-kappaB signaling")
barplot_top_enrich_terms(enrich_res_by_factor[[factor_indx]],
terms_of_interest = terms_of_interest,
str_wrap_length = 35) +
labs(title = paste0("Factor ", factor_indx))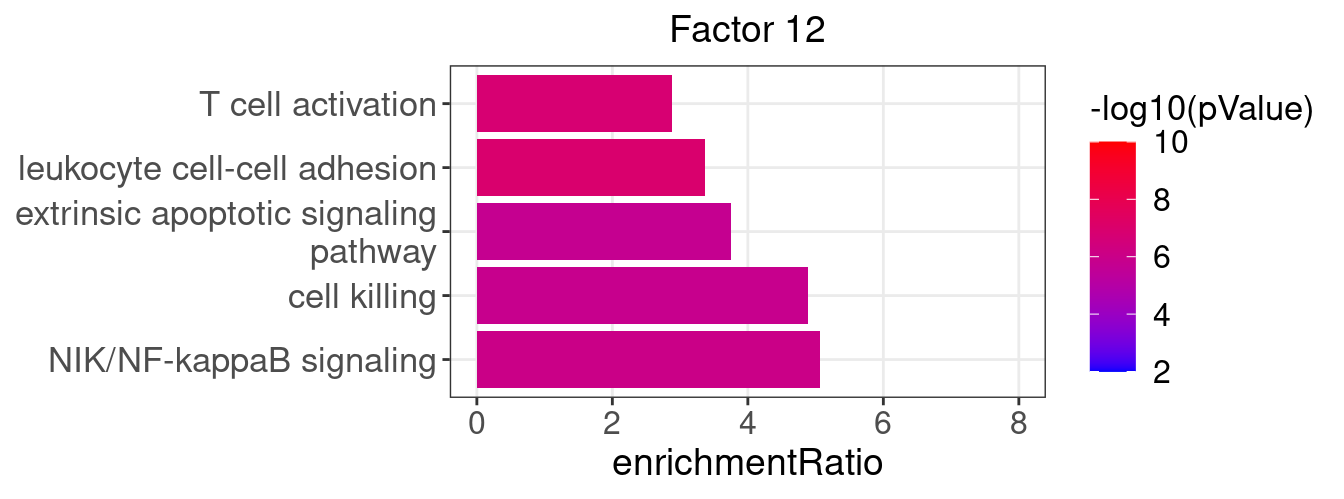
4 DEG Interpretation
In GSFA, differential expression analysis can be performed based on the LFSR method. Here we evaluate the specific downstream genes affected by the perturbations detected by GSFA.
We also performed several other differential expression methods for comparison, including scMAGeCK-LR, MAST, and DESeq.
Here, we compared the DEG results within stimulated cells.
4.1 Number of DEGs detected by different methods
fdr_cutoff <- 0.05
lfsr_cutoff <- 0.05| KO | ARID1A | BTLA | C10orf54 | CBLB | CD3D | CD5 | CDKN1B |
| Num_genes | 448 | 0 | 0 | 481 | 0 | 586 | 710 |
| KO | DGKA | DGKZ | HAVCR2 | LAG3 | LCP2 | MEF2D | NonTarget |
| Num_genes | 148 | 0 | 0 | 0 | 586 | 0 | 0 |
| KO | PDCD1 | RASA2 | SOCS1 | STAT6 | TCEB2 | TMEM222 | TNFRSF9 |
| Num_genes | 0 | 271 | 511 | 0 | 240 | 0 | 0 |
deseq_list <- readRDS(paste0(data_folder, "DE_result_DESeq2_stimulated.rds"))
deseq_signif_counts <- sapply(deseq_list, function(x){filter(x, FDR < fdr_cutoff) %>% nrow()})mast_list <- readRDS(paste0(data_folder, "DE_result_MAST_stimulated.rds"))
mast_signif_counts <- sapply(mast_list, function(x){filter(x, FDR < fdr_cutoff) %>% nrow()})scmageck_res <- readRDS(paste0(data_folder, "DE_result_scMAGeCK_stimulated.rds"))
colnames(scmageck_res$fdr)[colnames(scmageck_res$fdr) == "NegCtrl"] <- "NonTarget"
scmageck_signif_counts <- colSums(scmageck_res$fdr[, KO_names] < fdr_cutoff)dge_comparison_df <- data.frame(Perturbation = KO_names,
GSFA = lfsr_signif_num,
scMAGeCK = scmageck_signif_counts,
DESeq2 = deseq_signif_counts,
MAST = mast_signif_counts)
dge_comparison_df$Perturbation[dge_comparison_df$Perturbation == "NonTarget"] <- "NegCtrl"Number of DEGs detected under each perturbation using 4 different
methods:
Compared with other differential expression analysis methods, GSFA
detected the most DEGs for all 9 gene targets that have significant
effects.
dge_plot_df <- reshape2::melt(dge_comparison_df, id.var = "Perturbation",
variable.name = "Method", value.name = "Num_DEGs")
dge_plot_df$Perturbation <- factor(dge_plot_df$Perturbation,
levels = c("NegCtrl", KO_names[KO_names!="NonTarget"]))
ggplot(dge_plot_df, aes(x = Perturbation, y = Num_DEGs+1, fill = Method)) +
geom_bar(position = "dodge", stat = "identity") +
geom_text(aes(label = Num_DEGs), position=position_dodge(width=0.9), vjust=-0.25) +
scale_y_log10() +
scale_fill_brewer(palette = "Set2") +
labs(x = "Target genes",
y = "Number of DEGs",
title = "Number of DEGs detected by different methods") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 12),
legend.position = "bottom",
legend.text = element_text(size = 13))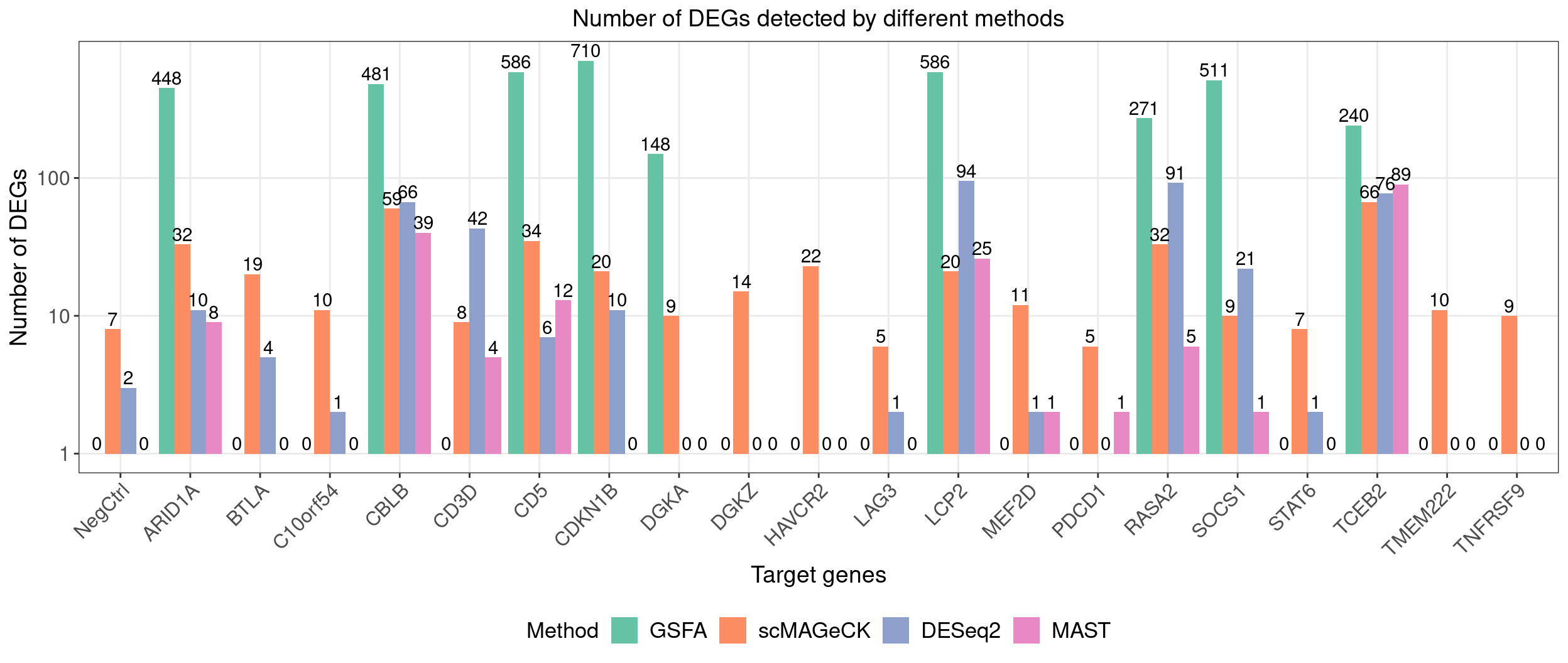
4.2 Perturbation effects on marker genes
To better understand the functions of these 7 target genes, we examined their effects on marker genes for T cell activation or proliferation states.
4.2.1 GSFA
Here are the summarized effects of perturbations on marker genes <<<<<<< HEAD estimated by GSFA.
======= estimated by GSFA (Figure 4D). >>>>>>> 04935ae6af7943cf9737a7c5374642526e41354aCell cycle:
As we can see, knockout of SOCS1 or CDKN1B has positive effects on cell
proliferation markers, indicating increased cell proliferation.
T cell activation and immune response:
Knockout of CD5, CBLB, RASA2 or TCEB2 has mostly positve effects on
effector markers, indicating T cell activation; knockout of ARID1A has
the opposite pattern.
complexplot_gene_perturbation(genes_df, interest_df,
targets = targets,
lfsr_mat = lfsr_mat1,
effect_mat = gibbs_PM$W_pm %*%
t(gibbs_PM$beta1_pm[-nrow(gibbs_PM$beta1_pm), ]))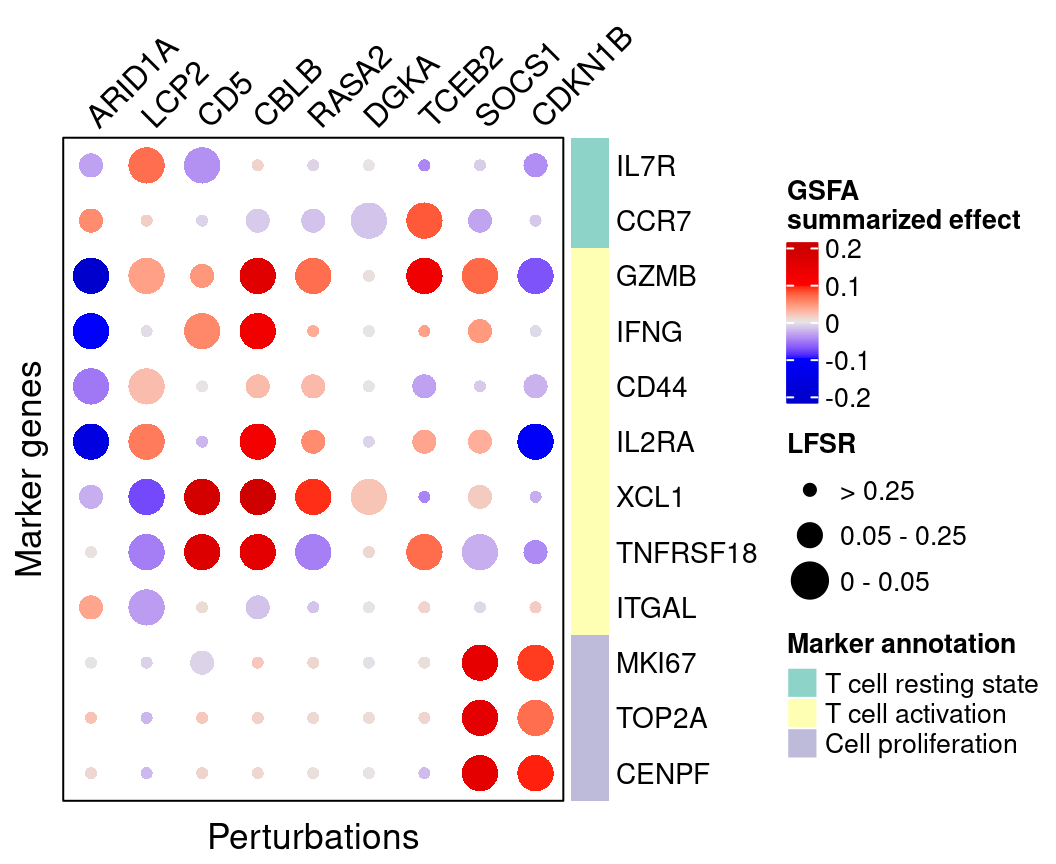
4.2.2 scMAGeCK
Here are scMAGeCK estimated effects of perturbations on marker genes:
score_mat <- scmageck_res$score
fdr_mat <- scmageck_res$fdr
complexplot_gene_perturbation(genes_df, interest_df,
targets = targets,
lfsr_mat = fdr_mat, lfsr_name = "FDR",
effect_mat = score_mat,
effect_name = "scMAGeCK\nselection score",
score_break = c(-0.2, 0, 0.2),
color_break = c("blue3", "grey90", "red3"))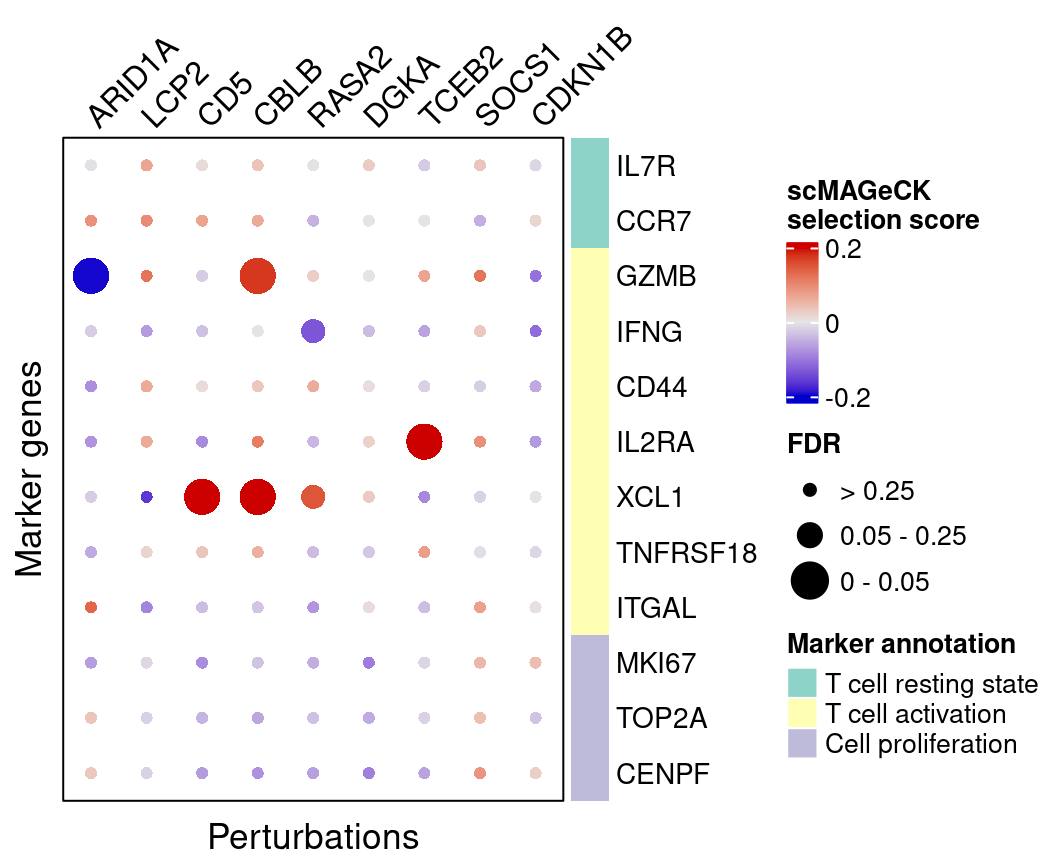
4.2.3 DESeq2
FC_mat <- matrix(nrow = nrow(interest_df), ncol = length(targets))
rownames(FC_mat) <- interest_df$gene_name
colnames(FC_mat) <- targets
fdr_mat <- FC_mat
for (m in targets){
FC_mat[, m] <- deseq_list[[m]]$log2FoldChange[match(interest_df$gene_ID,
deseq_list[[m]]$geneID)]
fdr_mat[, m] <- deseq_list[[m]]$FDR[match(interest_df$gene_ID,
deseq_list[[m]]$geneID)]
}Here are DESeq2 estimated effects of perturbations on marker genes:
complexplot_gene_perturbation(genes_df, interest_df,
targets = targets,
lfsr_mat = fdr_mat, lfsr_name = "FDR",
effect_mat = FC_mat, effect_name = "DESeq2 log2FC",
score_break = c(-0.4, 0, 0.4),
color_break = c("blue3", "grey90", "red3"))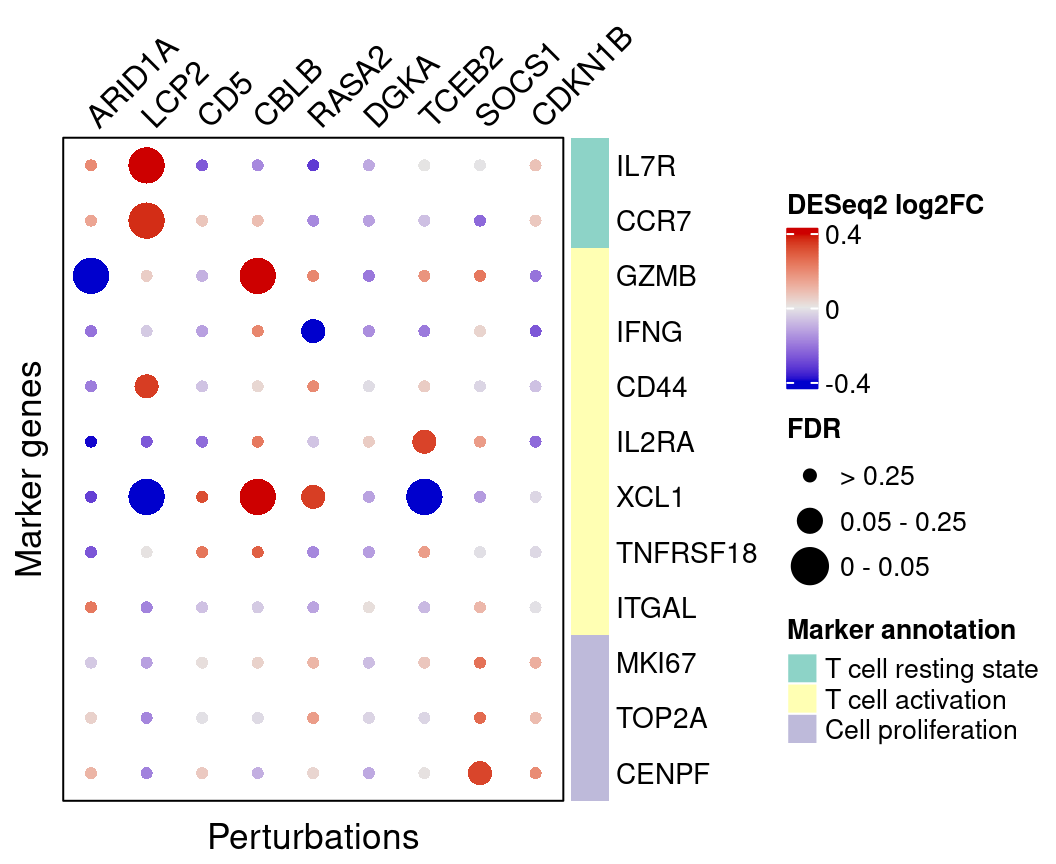
4.2.4 MAST
FC_mat <- matrix(nrow = nrow(interest_df), ncol = length(targets))
rownames(FC_mat) <- interest_df$gene_name
colnames(FC_mat) <- targets
fdr_mat <- FC_mat
for (m in targets){
FC_mat[, m] <- mast_list[[m]]$logFC[match(interest_df$gene_ID,
mast_list[[m]]$geneID)]
fdr_mat[, m] <- mast_list[[m]]$FDR[match(interest_df$gene_ID,
mast_list[[m]]$geneID)]
}MAST estimated effects of perturbations on marker genes:
=======MAST estimated effects of perturbations on marker genes (Figure S4E):
>>>>>>> 04935ae6af7943cf9737a7c5374642526e41354acomplexplot_gene_perturbation(genes_df, interest_df,
targets = targets,
lfsr_mat = fdr_mat, lfsr_name = "FDR",
effect_mat = FC_mat, effect_name = "MAST logFC",
score_break = c(-0.4, 0, 0.4),
color_break = c("blue3", "grey90", "red3"))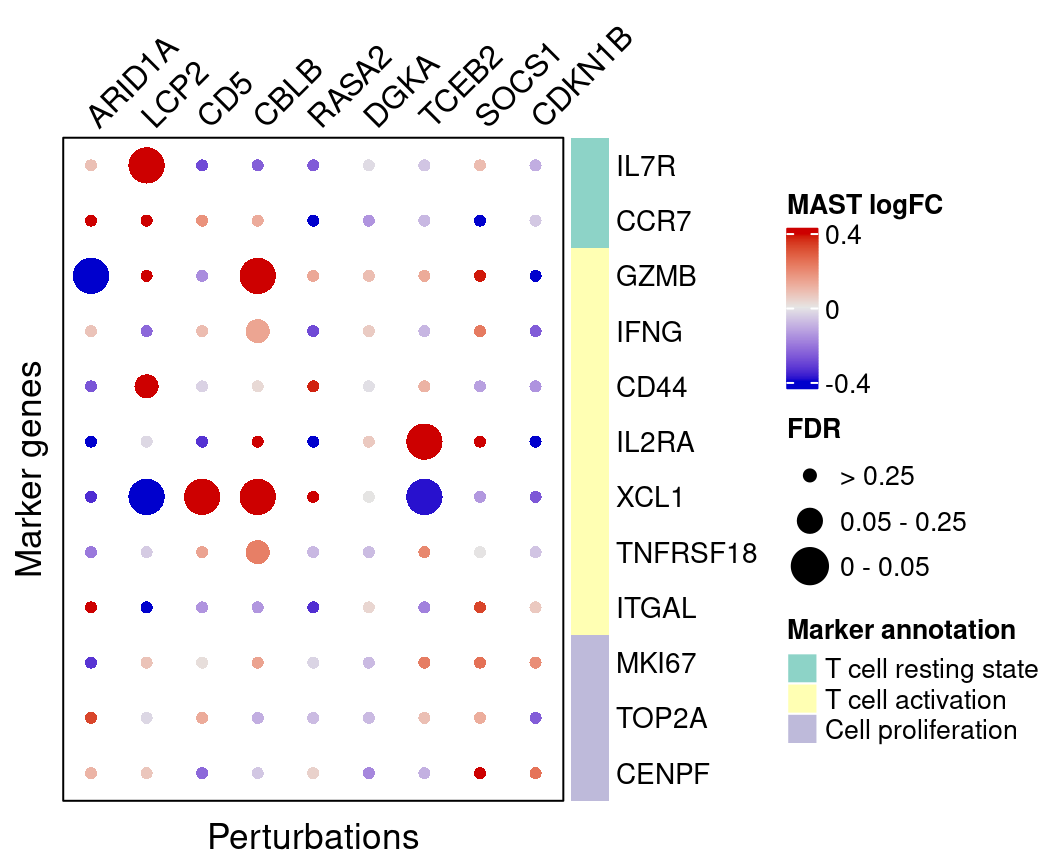
4.3 GO enrichment in DEGs
We further examine these DEGs for enrichment of relevant biological processes through GO enrichment analysis.
Foreground genes: Genes w/ GSFA LFSR < 0.05 under each
perturbation;
Background genes: all 6000 genes used in GSFA;
Statistical test: hypergeometric test (over-representation test);
Gene sets: GO Slim “Biological Process” (non-redundant).
## The "WebGestaltR" tool needs Internet connection.
targets <- names(lfsr_signif_num)[lfsr_signif_num > 0]
enrich_db <- "geneontology_Biological_Process_noRedundant"
enrich_res <- list()
for (i in targets){
print(i)
interest_genes <- genes_df %>% mutate(lfsr = lfsr_mat1[, i]) %>%
filter(lfsr < lfsr_cutoff) %>% pull(ID)
enrich_res[[i]] <-
WebGestaltR::WebGestaltR(enrichMethod = "ORA",
organism = "hsapiens",
enrichDatabase = enrich_db,
interestGene = interest_genes,
interestGeneType = "ensembl_gene_id",
referenceGene = genes_df$ID,
referenceGeneType = "ensembl_gene_id",
isOutput = F)
}signif_GO_list <- list()
for (i in names(enrich_res)) {
signif_GO_list[[i]] <- enrich_res[[i]] %>%
dplyr::filter(FDR < 0.05) %>%
dplyr::select(geneSet, description, size, enrichmentRatio, pValue) %>%
mutate(target = i)
}
signif_term_df <- do.call(rbind, signif_GO_list) %>%
group_by(geneSet, description, size) %>%
summarise(pValue = min(pValue)) %>%
ungroup()
abs_FC_colormap <- circlize::colorRamp2(breaks = c(0, 3, 6),
colors = c("grey95", "#77d183", "#255566"))enrich_table <- data.frame(matrix(nrow = nrow(signif_term_df),
ncol = length(targets)),
row.names = signif_term_df$geneSet)
colnames(enrich_table) <- targets
for (i in 1:ncol(enrich_table)){
m <- colnames(enrich_table)[i]
enrich_df <- enrich_res[[m]] %>% filter(enrichmentRatio > 2)
enrich_table[enrich_df$geneSet, i] <- enrich_df$enrichmentRatio
}
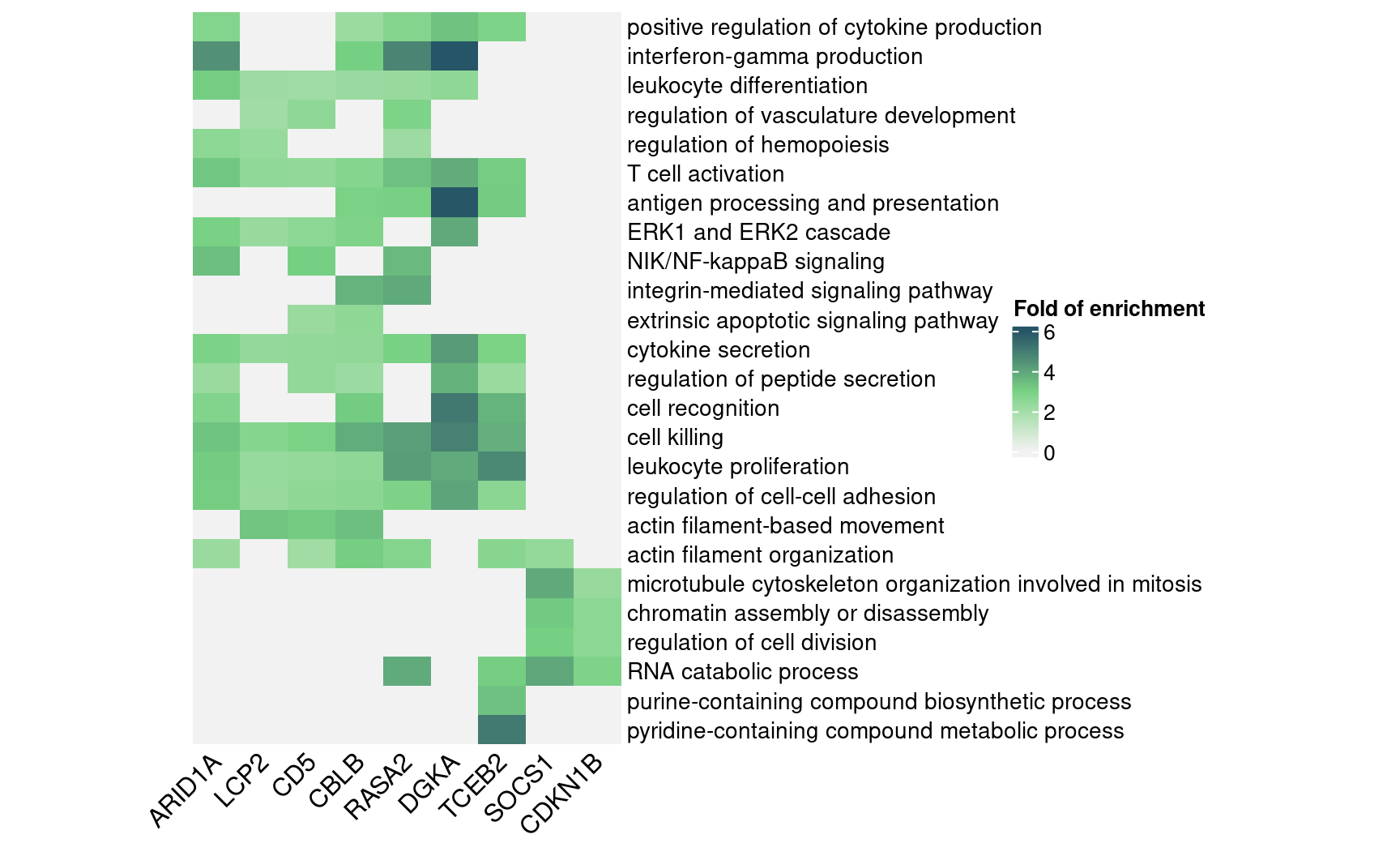
rownames(enrich_table) <- signif_term_df$descriptionHere are selected GO “biological process”” terms and their folds of
enrichment in DEGs detected by GSFA.
(In the code below, we omitted the content in
terms_of_interest_df as one can subset the
enrich_table with any terms of their choice.)
interest_enrich_table <- enrich_table[terms_of_interest_df$description, ]
interest_enrich_table[is.na(interest_enrich_table)] <- 0
map <- Heatmap(interest_enrich_table,
name = "Fold of enrichment",
col = abs_FC_colormap,
row_title = NULL, column_title = NULL,
cluster_rows = F, cluster_columns = F,
show_row_dend = F, show_column_dend = F,
show_heatmap_legend = T,
row_names_gp = gpar(fontsize = 10.5),
column_names_rot = 45,
width = unit(7, "cm"))
draw(map, heatmap_legend_side = "right")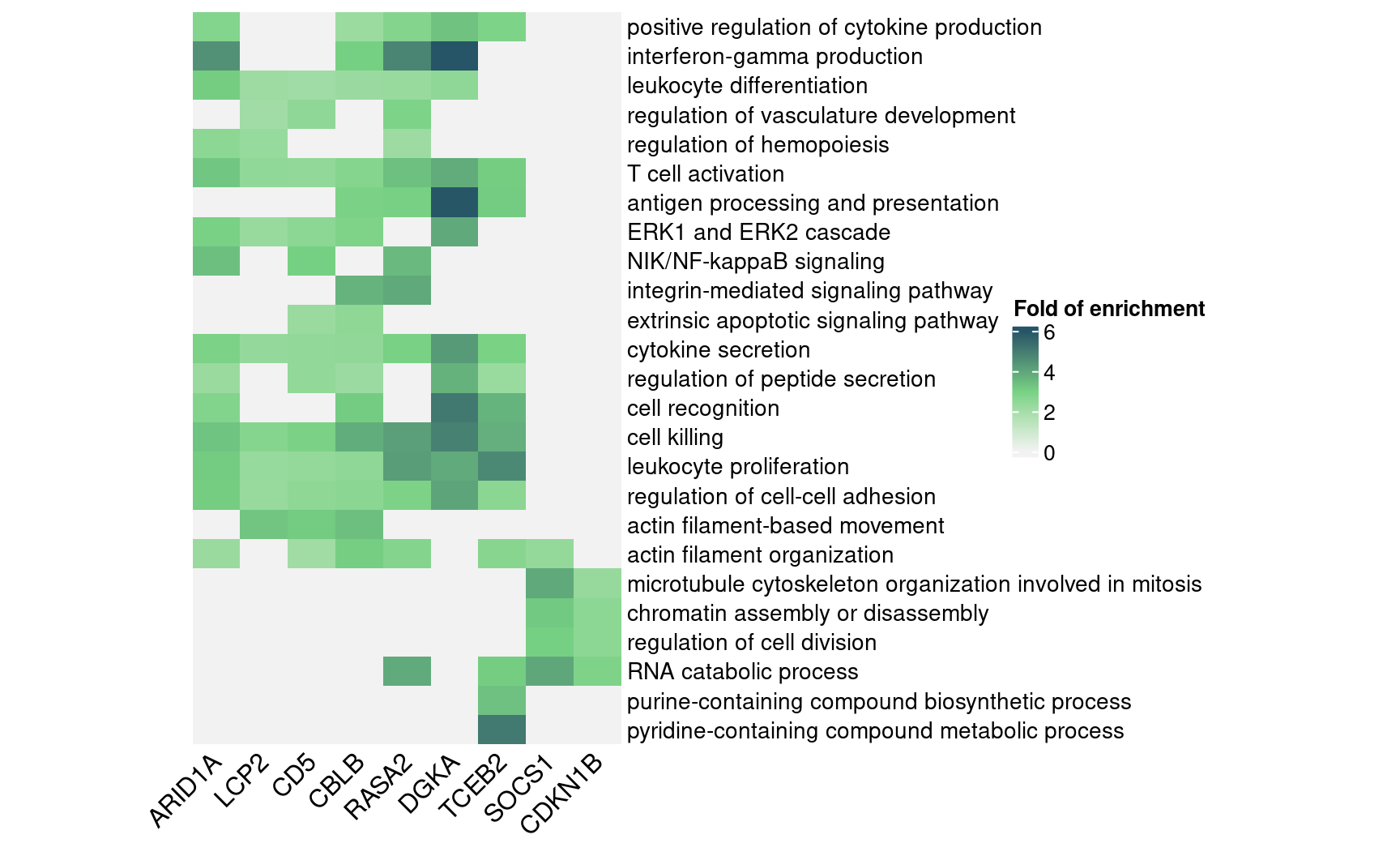
5 Session Information
sessionInfo()R version 4.2.0 (2022-04-22)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.3.13-el7-x86_64/lib/libopenblas_haswellp-r0.3.13.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=C
[4] LC_COLLATE=C LC_MONETARY=C LC_MESSAGES=C
[7] LC_PAPER=C LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C LC_IDENTIFICATION=C
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] lattice_0.20-45 WebGestaltR_0.4.4 kableExtra_1.3.4
[4] ComplexHeatmap_2.12.0 gridExtra_2.3 forcats_1.0.0
[7] stringr_1.5.0 dplyr_1.1.0 purrr_1.0.1
[10] readr_2.1.4 tidyr_1.3.0 tibble_3.1.8
[13] ggplot2_3.4.1 tidyverse_1.3.2 Matrix_1.5-3
[16] data.table_1.14.6
loaded via a namespace (and not attached):
[1] matrixStats_0.63.0 fs_1.6.1 lubridate_1.9.2
[4] webshot_0.5.3 doParallel_1.0.17 RColorBrewer_1.1-3
[7] httr_1.4.4 doRNG_1.8.6 tools_4.2.0
[10] backports_1.4.1 bslib_0.4.2 utf8_1.2.3
[13] R6_2.5.1 DBI_1.1.3 BiocGenerics_0.44.0
[16] colorspace_2.1-0 GetoptLong_1.0.5 withr_2.5.0
[19] tidyselect_1.2.0 compiler_4.2.0 cli_3.6.0
[22] rvest_1.0.3 Cairo_1.6-0 xml2_1.3.3
[25] labeling_0.4.2 sass_0.4.5 scales_1.2.1
[28] apcluster_1.4.10 systemfonts_1.0.4 digest_0.6.31
[31] svglite_2.1.0 rmarkdown_2.20 pkgconfig_2.0.3
[34] htmltools_0.5.4 highr_0.10 dbplyr_2.3.0
[37] fastmap_1.1.0 rlang_1.0.6 GlobalOptions_0.1.2
[40] readxl_1.4.2 rstudioapi_0.14 farver_2.1.1
[43] shape_1.4.6 jquerylib_0.1.4 generics_0.1.3
[46] jsonlite_1.8.4 googlesheets4_1.0.1 magrittr_2.0.3
[49] Rcpp_1.0.10 munsell_0.5.0 S4Vectors_0.36.1
[52] fansi_1.0.4 lifecycle_1.0.3 whisker_0.4
[55] stringi_1.7.12 yaml_2.3.7 plyr_1.8.7
[58] parallel_4.2.0 crayon_1.5.2 haven_2.5.1
[61] pander_0.6.5 circlize_0.4.15 hms_1.1.2
[64] knitr_1.42 pillar_1.8.1 igraph_1.4.0
[67] rjson_0.2.21 rngtools_1.5.2 reshape2_1.4.4
[70] codetools_0.2-18 stats4_4.2.0 reprex_2.0.2
[73] glue_1.6.2 evaluate_0.20 modelr_0.1.10
[76] png_0.1-8 vctrs_0.5.2 tzdb_0.3.0
[79] foreach_1.5.2 cellranger_1.1.0 gtable_0.3.1
[82] clue_0.3-61 assertthat_0.2.1 cachem_1.0.6
[85] xfun_0.37 broom_1.0.3 viridisLite_0.4.1
[88] googledrive_2.0.0 gargle_1.3.0 iterators_1.0.14
[91] IRanges_2.32.0 cluster_2.1.3 timechange_0.2.0
[94] ellipsis_0.3.2